OmniGraph Architecture¶
Fabric¶
As mentioned in the introduction, one of the key dependencies that OmniGraph has is Fabric. While not doing it justice, in a nutshell Fabric is a cache of USD data in vectorized, compute friendly form. OmniGraph leverages Fabric’s data vectorization feature to help optimize its performance. Fabric also facilitates the movement of data between CPU and GPU, allowing data to migrate between the two in a transparent manner.
There are currently two kinds of caches. There is a single StageWithHistory cache in the whole system, and any number of StageWithoutHistory caches.
When a graph is created, it must specify what kind of Fabric cache “backs” it. All the data for the graph will be stored in that cache.
USD¶
Like the rest of Omniverse, OmniGraph interacts with and is highly compatible with USD. We use USD for persistence of the graph. Moreover, since Fabric is essentially USD in compute efficient form, any transient compute data can be “hardened” to USD if we so choose. That said, while it is possible to do so, we recommend that node writers refrain from accessing USD data directly from the node, as USD is essentially global data, and accessing it from the node would prevent it from being parallel scheduled and thus get in the way of scaling and distribution of the overall system.
Data model¶
The heart of any graph system is its data model, as it strictly limits the range of compute expressible with the graph. Imagine what sort of compute can be expressed if the graph can only accept two integers, for example. OmniGraph supports a range of options for the data coursing through its connections.
Regular attributes¶
As the most basic and straightforward, you can predeclare any attributes supported by USD on the node. Give it a name, a type, and a description, and that’s pretty much all there is to it. OGN will synthesize the rest. While straightforward, this option limits the data to that which is predeclared, and limits the data types to the default ones available in USD.
Bundle¶
To address the limitations of “regular” attributes, we introduced the notion of the “bundle”. As the name suggests, this is a flexible “bundle” of data, similar to a prim. One can dynamically create any number of attributes inside the bundle and transport that data down the graph. This serves two important purposes. First, the system becomes more flexible - we are no longer limited to pre-declared data. Second, the system becomes more usable. Instead of many connections in the graph, we have just a single connection, with all the necessary data that needs to be transported.
Extended Attributes¶
While bundles are flexible and powerful, they are still not enough. This is because its often desirable to apply a given set of functionality against a variety of data types. Think, for example, the functionality to add things. While the concept is the same, one might want to add integers, floats, and arrays of them, to name a few. It would be infeasible to create separate nodes for each possible type. Instead, we create the notion of extended attributes, where the attribute has just an unresolved placeholder at node creation time. Once the attribute is connected to another, regular attribute, it resolves to the type of that regular attribute. Note that extended attributes will not extend to bundles.
Dynamic Attributes¶
Sometimes, it is desirable to modify an individual node instance rather than the node type. An example is a script node, where the user wants to just type in some bits of Python to create some custom functionality, without going through the trouble of creating a new node type. To this end it would be really beneficial to just be able to add some custom attributes onto the node instance (as opposed to the node type), to customize it for use. Dynamic attributes are created for this purpose - these are attributes that are not predeclared, and do not exist on the node type, but rather tacked on at runtime onto the node instance.
OGN¶
Node systems come with a lot of boilerplate. For example, for every attribute one adds on a node, there needs to be code to create the attribute, initialize its value, and verify its value before compute, as a few examples. If the node writer is made responsible for these mundane tasks, not only would that add substantially to the overall cost of writing and maintaining the node, but also impact the robustness of the system overall as there may be inconsistencies/errors in how node writers go about implementing that functionality.
Instead, we created a code synthesizing system named OGN (OmniGraph Nodes) to alleviate those issues. From a single json description of the node, OGN is able to synthesize all the boilerplate code to take the burden off developers and keep them focused on the core functionality of the node. In addition, from the same information, OGN is able to synthesize the docs and the tests for the node if the node writer provides it with expected inputs and outputs.
OmniGraph is a graph of graphs¶
Due to the wide range of use cases it needs to handle, a key design goal for OmniGraph is to able to create graphs of any kind, and not just the traditional flow graphs. To achieve this goal, OmniGraph maintains strict separation between graph representation and graph evaluation. Different evaluators can attach different semantics to the graph representation, and thus create any kind of graph. Broadly speaking, graph evaluators translate the graph representation into schedulable tasks. These tasks are then scheduled with the scheduling component.
Unfortunately, as of this writing this mechanism has not been fully exposed externally. Creating new graph types still requires modification to the graph core. That said, we have already created several graph types, including busy graph (push), lazy evaluation graph (dirty_push), and event handling graph (action).
Although it’s desirable to be able to create different graph types, the value of the different graph types would be diminished if they didn’t interact with each other. To this end, OmniGraph allows graphs to interact with each other by coordinating the tasks each graph generates. The rule is that each parent graph defines the rules by which tasks from subgraphs will coordinate with its own. Practically speaking, this means that current graph types are interoperable with one another. For example it is possible to combine a lazy evaluation graph with a busy evaluation graph, by constructing the lazy evaluation graph as a subgraph of the busy one - this allows part of the overall graph to be lazy and part of it to be busy. The lazy part of the graph will only be scheduled if someone touches some node in the graph, whereas the busy part will be scheduled always.
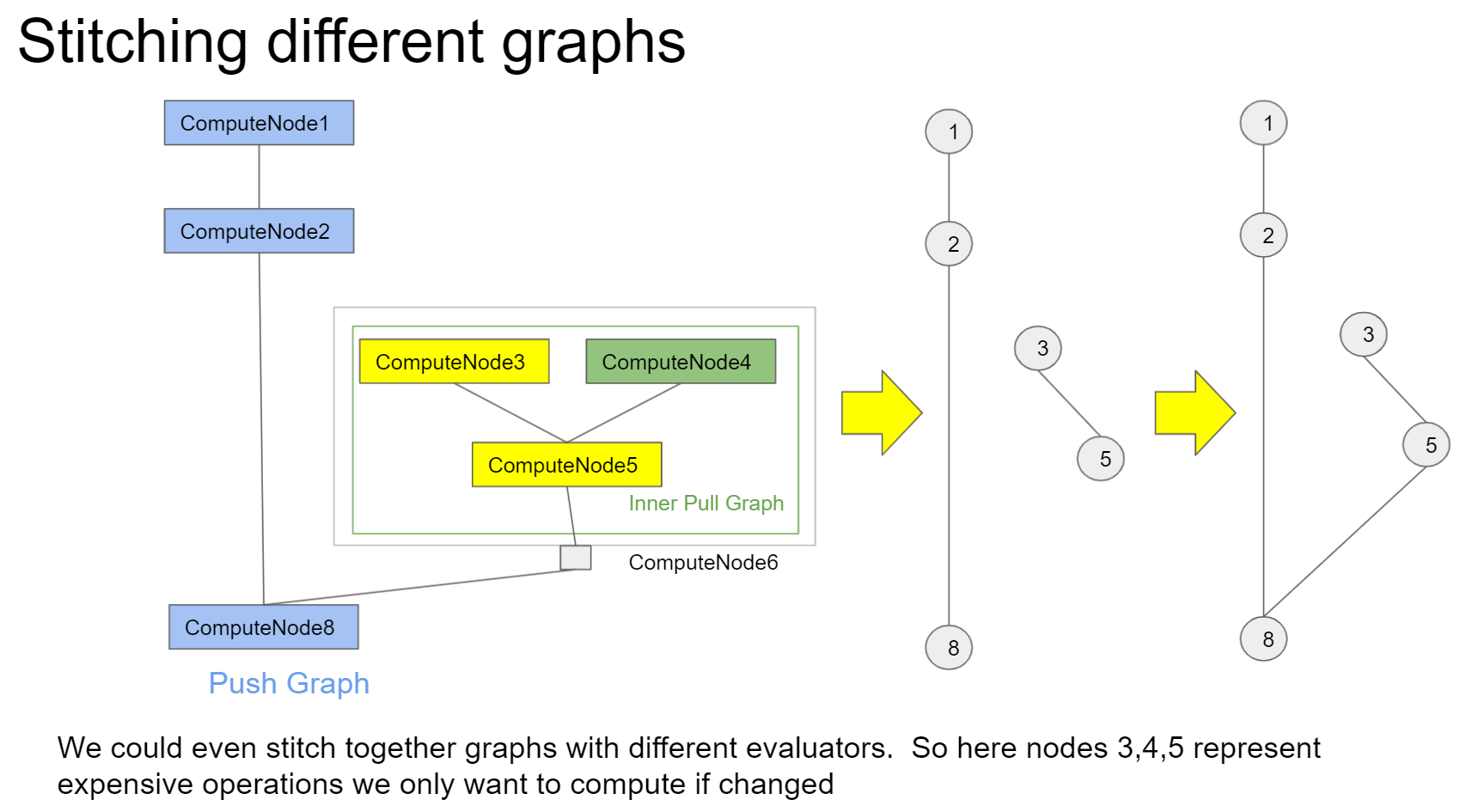
The diagram below ties the concepts together - here we have two graphs interacting with each other. The outer blue, push graph and the inner green lazy evaluation graph. Through graph evaluation (the first yellow arrow), the nodes are translated to tasks. Here the rectangles are nodes and circles are tasks. Note that the translation of the outer graph is trivial - each node just maps to 1 task. The inner lazy graph is slightly more complicated - only those nodes that are dirty (marked by yellow) have tasks to be scheduled (tasks 3,5). Finally, through the graph stitching mechanism, task 5 is joined to task 8 as one of its dependencies:
push Graph¶
This is the simplest of graph types. Nodes are translated to tasks on a one to one basis every single frame, causing all nodes in the graph to be scheduled.
dirty_push Graph¶
This is a lazy evaluation graph. When nodes are modified, they send dirty bits downstream, just like traditional pull graphs as in Maya or Houdini, if the reader is familiar with those systems. However, unlike standard pull graphs, all dirtied nodes are scheduled, rather than the subset whose output is requested as in standard pull graphs. This is due to the fact that our viewport is not yet setup to generate the “pull”. That said, just by scheduling only the dirtied nodes, this graph already goes most of the way in terms of minimizing the amount of work by not scheduling nodes that have not changed.
action graph¶
This is a graph type that is able to respond to events, such as mouse clicked or time changed. In response to these events, we can trigger certain downstream nodes into executing. The graph works in a similar way to Blueprints in UnReal Engine, in case the user is familiar with that system. This graph contains specialized attributes (execution) that allow users to describe the execution path upon receipt of an event. Action graphs also supports constructs such as branching and looping.
Subgraphs¶
Currently subgraphs can be defined within the scope of its parent graph, and can be of a different type of graph than its parent. As mentioned in the previous section, it’s up to the parent graph to define the rules of interoperability, if any, between itself and the subgraphs it contains. Note that currently there are no rules defined between sibling subgraphs, and any connections between nodes of sibling subgraphs can lead to undefined behavior.
Pipeline Stages¶
Graphs are currently organized into several categories, also called “pipeline stages”. There are currently 4 pipeline stages: simulation, pre-render, post-render, and on-demand. Graphs in the simulation pipeline stage are run before those in pre-render which in turn are run before those in post-render. When a pipeline stage runs, all the graphs contained in the pipeline stage are evaluated. The on-demand pipeline stage is a collection of graphs that aren’t run in the above described order. Instead, are individually run at an unspecified time. The owner of the graphs in the on-demand stage are responsible for calling evaluate on the graph and thus “ticking” them.
Global Graphs¶
Within each pipeline stage, there may be a number of graphs, all independent of each other. Each of these independent graphs are known as a global graph. Each of the global graphs may contain further subgraphs that interoperate with each other in the above described manner. Global graphs are special in two ways:
They may have their own Fabric. When the global graph is created, it can specify whether it wants to use the “StageWithHistory” cache, or its very own “StageWithoutHistory” cache. All subgraphs of the global graph must choose the “shared” Fabric setting, to share the cache of its parent global graph. Since there is only one StageWithHistory cache, specifying the shared option with a global graph is the same as specifying the StageWithHistory option.
They handle USD notices
Currently, all subgraphs must share the Fabric cache of the parent global graph, and they do not handle their own USD notices. Global graphs that have their own cache can always be run in parallel in a threadsafe way. Global graphs that share a Fabric cache must be more careful - currently update operations (say moving an object by updating its transform) are threadsafe, but adding / deleting things from the shared Fabric are not.
Orchestration Graph¶
Within a pipeline stage, how do we determine the order of execution of all the global graphs contained in it? The answer is the orchestration graph. Each global graph is wrapped as a node in this orchestration graph. By default, all the nodes are independent, meaning the graphs can potentially execute in parallel, independent of each other. However, if ordering is important, the nodes that wrap the graph may introduce edges to specify ordering of graph execution. While graphs in the on-demand pipeline stage also do have an orchestration graph, no edges are permitted in here as the graphs in this stage aren’t necessarily executed together.
Python¶
All of OmniGraph’s functionality is fully bound to Python. This allows scripting, testing in Python, as well as writing of nodes in Python. Python is a first class citizen in OmniGraph. The full Python API and commands are documented here:
Scheduling¶
As OmniGraph separates graph evaluation from graph representation, it also separates scheduling concerns from the other pieces. Once the graph evaluator does its job and translates the graph representation into tasks, we can schedule those tasks through any number of means.
Static serial scheduler¶
This is the simplest of the schedulers. It schedules tasks serially, and does not allow modification of the task graph.
Realm scheduler¶
This scheduler takes advantage of the Realm technology (super efficient microsecond level efficient scheduler) to parallel schedule the tasks.
Dynamic scheduler¶
The dynamic scheduler allows the modification of the task graph at runtime, based on results of previous tasks. Currently the modification is limited to canceling of future tasks already scheduled.
Extensions¶
Although you can see these in the extension window it is cluttered up with non-OmniGraph extensions. This is a distillation of how all of the omni.graph.XXX extensions depend on each other. Dotted lines represent optional dependencies. Lines with numbers represent dependencies on specific extension version numbers. Lines with Test Only represent dependencies that are only enabled for the purposes of running the extension’s test suite.